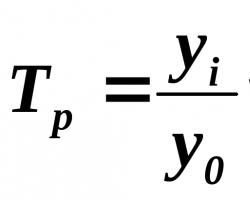Объектами статистических исследований являются статистические совокупности, состоящие из отдельных единиц, характеризуемых различными признаками. В результате исследований выявляются статистические закономерности, на основе использования моделей социально-экономических явлений и методов обработки и анализа экономико-статистической информации.
Статистическая совокупность - множество объектов, явлений, объединенных какими-либо общими свойствами (признаками) и подвергающихся статистическому исследованию. Например, совокупность промышленных предприятий страны. Отдельные объекты явления, составляющие статистическую совокупность и называемые единицами совокупности, обладая некоторыми общими признаками, могут различаться между собой по другим признакам. Поэтому совокупности могут быть однородными (качественно однородными) и неоднородными (качественно неоднородными).
В однородной совокупности объекты (единицы совокупности) сходны между собой по существенным для данного исследования признакам и относятся к одному и тому же типу явления. Однородная совокупность, будучи однородной по одним признакам, может быть разнородной по другим.
Элементы (единицы) неоднородной совокупности относятся к различным типам изучаемых явлений. Для неоднородной совокупности исчисление обобщающих характеристик, в особенности в виде средней величины, неправомерно. С помощью метода группировок и метода таксономии в неоднородной совокупности могут быть образованы однородные группы.
Вся совокупность реально существующих объектов, характеризующих какое-либо явление, называется генеральной. Для статистического исследования из генеральной совокупности по определенным правилам может быть отобрана совокупность единиц, которые образуют выборочную совокупностью.
Каждая единица совокупности характеризуется различными признаками - отличительными чертами, свойствами, качеством.
Варьирующий признак - признак, принимающий в пределах статистической совокупности разные значения у единиц статистической совокупности. Это, однако, не исключает повторений отдельных значений (вариантов) признака, у нескольких единиц совокупности значения признака могут быть одинаковыми. Примером варьирующего признака может служить размер месячной заработной платы рабочих предприятия.
Качественный признак (атрибутивный) - признак, отдельные значения которого выражаются в виде понятий, наименований. Например, профессия рабочего (слесарь, сборщик), уровень образования (начальное, среднее, высшее).
Количественный признак - признак, отдельные значения которого имеют количественное выражение (например, себестоимость продукции по различным предприятиям одной отрасли).
Результативный признак - зависимый признак, то есть изменяющий свое значение под влиянием другого, связанного с ним факторного признака.
Факторный признак (фактор) - признак, оказывающий влияние на другой, связанный с ним результативный признак, и обусловливающий его изменение (вариацию). Роль этих признаков в различных задачах может меняться, в одной задача он выступает как факторный, в другой - как результативный. Например, производительность труда выступает фактором изменения (снижения) себестоимости единицы продукции, и в то же время, производительность труда в связи с квалификацией рабочего является результативным признаком.
В результате статистического исследования устанавливается статистическая закономерность, которая рассматривается как количественная закономерность изменения в пространстве и во времени массовых явлений и процессов общественной жизни, состоящих из множества элементов (единиц совокупности). Она свойственна не отдельным единицам совокупности, а всей совокупности в целом. В силу этого закономерность, присущая данному явлению (процессу), проявляется только при достаточно большом числе наблюдений и только в среднем. Таким образом, это средняя закономерность массовых явлений и процессов. В большом числе наблюдений происходит взаимопогашение индивидуальных отклонений от средней в ту и другую стороны, вызванных случайными причинами, и проявляется закономерность. Это связывает статистическую закономерность с законом больших чисел, По мере увеличения пространственно-временных интервалов развития явления его закономерность становится все более устойчивой.
Таким образом, зная статистическую закономерность конкретного массового явления, можно с определенной вероятностью предвидеть его дальнейшее развитие, определить величину изучаемого признака (показателя). Однако необходимо учитывать, что значительные изменения условий существования этого явления могут привести к существенным изменениям силы этой зависимости.
В социально-экономической статистике закон больших чисел представляет собой общий принцип, в силу которого количественные закономерности, присущие массовым общественным явлениям, отчетливо проявляются лишь в достаточно большом числе наблюдений. Закон больших чисел порожден особыми свойствами массовых социальных явлений. Последние в силу своей индивидуальности, с одной стороны, отличаются друг от друга, а с другой - имеют нечто общее, обусловленное их принадлежностью к определенному виду, классу, к определенным группам. Единичные явления в большей степени подвержены воздействию случайных и несущественных факторов, чем масса в целом. В большом числе наблюдений взаимно погашаются случайные отклонения в противоположные стороны от закономерностей. В результате взаимопогашения случайных отклонений средние, вычисленные для величин одного и того же вида, становятся типичными, отражающими действие постоянных и существенных факторов в данных условиях места и времени. Тенденции и закономерности, вскрытые с помощью закона больших чисел - это массовые статистические тенденции.
Статистическое исследование социально-экономических явлений осуществляется различными методами с использованием моделей этих явлений.
Моделью называется отображение, аналог явления или процесса в основных, существенных для целей исследования чертах. Процесс создания модели называется моделированием. Модель должна учитывать все важные взаимосвязи, закономерности и условия развития таким образом, чтобы на ее основе можно было выполнить эксперименты, цель которых - определение “поведения” объекта моделирования в различных возможных (часто ненаблюдаемых в действительности) условиях. Экономические явления и процессы моделируются с помощью экономико-математических моделей.
Экономико-математическая модель - описание экономического явления или процесса с помощью одного или нескольких математических выражений (уравнений, функций, неравенств, тождеств). Математические выражения характеризуют важнейшие взаимосвязи явлений и процессов, условия и закономерности их развития, ограничения, требования и т.д. Экономико-математическая модель представляет собой обобщение существенной качественной и количественной информации об объекте анализа и служит базой для проведения расчетных экспериментов, которые позволяют получить различные характеристики и параметры изучаемого объекта для заданных условий его развития. Разработка и применение экономико-математических моделей существенно расширяют возможности экономического анализа. Основные преимущества использования экономико-математических моделей заключаются в следующем:
Одновременный учет в модели большого числа требований, условий и предположений, а также достаточная свобода в пересмотре этих условий в ходе работы с моделью;
Непротиворечивость (совместность) получаемых по модели системы показателей;
Возможность получения вариантов поведения изучаемого явления для широкого диапазона и сочетания исходных условий и предположений (например, вариантов прогноза экономического развития).
Экономико-математические модели по назначению делятся на теоретико-экономические и прикладные модели. Многие прикладные модели являются экономико-статистическими моделями или включают последние в качестве составных частей.
Теоретико-экономические - это экономико-математические модели, предназначенные для качественного анализа экономических систем, процессов и явлений, Значения параметров и даже функциональный вид входящих в теоретико-экономическую модель соотношений обычно не конкретизируется. Выводы, которые получаются с помощью этих моделей, как правило, носят общий характер. Типичным примером является вывод об устойчивости (неустойчивости) изучаемой экономической системы, если ее параметры удовлетворяют определенным требованиям, о существовании (отсутствии) сбалансированных или оптимальных решений. Теоретико-экономические модели широко используются в теоретических экономических исследованиях. В настоящее время построение и исследование теоретико-экономических моделей является предметом математической экономики. Для их исследования применяется развитый математический аппарат (теория дифференциальных уравнений, теория матриц, оптимизационные и теоретико-игровые методы и т.д.).
Экономико-статистическая модель - это система математических соотношений, описывающая некоторый экономический объект, процесс или явление, параметры которой определяются (оцениваются) на основе фактических данных с помощью статистических данных (в отличие от теоретико-экономической модели). Структура и конкретный вид экономико-статистической модели определяются спецификой моделируемого объекта, теоретическими представлениями исследователя, целями исследования, доступностью информации, используемыми методами обработки данных. Процесс построения модели распадается на два взаимосвязанных этапа: определение общего вида соотношений модели и входящих в них переменных и статистическое оценивание значений параметров на основе данных наблюдений. К наиболее часто используемым экономико-статистическим моделям относятся тренды, модели временных рядов, изолированные уравнения регрессии, эконометрические модели. Экономико-статистические модели широко применяются при планировании и анализе экономических систем, исследовании их реакции на изменение внешних и внутренних условий функционирования, а также при прогнозировании и определении различных вариантов будущего развития.
Для оценивания параметров эконометрической модели необходимы специальные методы одновременного оценивания (доказано, что обычный метод наименьших квадратов, примененный к каждому уравнению эконометрической модели изолированно, приводит к несостоятельным оценкам). Наиболее употребительными методами одновременного оценивания эконометрической модели являются двухшаговый и трехшаговый метод наименьших квадратов.
Одной из отличительных черт бурного развития науки является широкое применение статистических методов и вычислительной техники в освоении информации. В настоящее время невозможно представить себе дисциплину, которая не пользовалась бы в процессе познания методами численного выражения закономерностей, связей, зависимости, измерения тенденции и т. д. Это, в частности, относится и к экономическим наукам.
В статистической литературе большое внимание уделяется изучению и применению отдельных статистических методов и приемов, но совсем недостаточно освещены вопросы целесообразности и последовательности использования того или иного статистического метода, их комплексного применения, сочетания различных методов. Абсолютизация того или иного метода исследования ничего, кроме вреда, не приносит. Только сочетание различных методов может дать заметный эффект. Именно с этих позиций и нужно оценивать роль и место статистического моделирования в системе познания различных процессов и явлений. В данной работе предпринята попытка систематизировать методику комплексного применения статистических методов в экономических исследованиях, рассмотрена целесообразность и последовательность использования статических методов и приемов при анализе статических и динамических процессов.
Первым этапом исследования является накопление (сбор) необходимых сведений об изучаемом объекте. Если наблюдений не очень много, то можно провести упорядочение, расположив их в порядке возрастания или убывания, т. е. построить ранжированные ряды. Если же наблюдений много, то приходится прибегать к их группировке. Статистические ряды носят самый разнообразный характер, имеют различное назначение и в разных целях могут использоваться в экономическом анализе. Одни статистические ряды являются вариационными рядами распределения. Эти ряды показывают распределение единиц изучаемой совокупности по отдельным группам, выделенным по какому-либо признаку. Другой разновидностью статистических рядов является последовательность чисел, отражающих величину того или иного показателя во времени. Это так называемые ряды динамики. Они позволяют анализировать изменение любых явлений во времени, об этом речь пойдет позже. Не умаляя значения временных рядов, следует отметить, что вариационным рядам распределения в статистическом анализе принадлежит особое место, ибо только при помощи распределения сложных совокупностей на качественно однородные группы можно изучать их структуру, соотношение между частями целого и т. п., без чего немыслим никакой экономический анализ. Ряды распределения могут строиться по качественным (атрибутивным) и по количественным признакам, по одному признаку и по нескольким, предоставляя тем самым широкие возможности исследователям при изучении сложных экономических явлений. Ряды распределения могут быть представлены либо в табличной форме, либо в геометрической, т. е. графической. Статистическая совокупность, представленная в виде ранжированного ряда распределения, графически изображается в виде огивы. Она строится так: на оси абсцисс наносятся номера элементов совокупности по ранжиру, а на оси ординат откладываются значения признака. Огива наглядно показывает интенсивность изменения изучаемого признака. Вариационные ряды распределения изображаются графически в виде полигонов и гистограмм. В виде полигонов обычно изображаются дискретные вариационные ряды распределения. При этом значения признака откладывают на оси абсцисс, а частоты (или частости) – на оси ординат. Вершины ординат соединяют прямыми линиями, в результате чего получают полигон (многоугольник). В виде полигона можно представить и интервальные вариационные ряды. Для этого за отдельные значения признака принимаются средние значения интервалов. Интервальные же вариационные ряды чаще всего изображают в виде гистограммы, в которой частоты выражают в виде прямоугольников соответствующей длины, а основания прямоугольников, опирающиеся на ось абсцисс, соответствуют интервалу значения признака (рис. 1).
Рис. 1. Гистограмма и полигон распределения
Различают одновершинные и многовершинные распределения. Многовершинность распределения, как правило, является признаком неоднородности изучаемой совокупности. Из разнообразия форм одновершинных кривых распределений можно выделить следующие наиболее характерные типы: симметричные, умеренно асимметричные, крайне асимметричные.
В практике обычно редко встречаются идеально симметричные распределения, чаще умеренно асимметричные, в которых частоты с одной стороны от центра рассеивания уменьшаются заметно быстрее, чем с другой. Асимметричное распределение в пределе становится крайне асимметричным – в этом случае наибольшая частота расположена на одном из концов распределения.
При решении некоторых вопросов удобнее пользоваться накопленными частотами распределения. Кривая накопленных частот распределения носит название «кумулята распределения». При построении кумуляты на оси абсцисс откладываются значения признака, на оси ординат – накопленные частоты. Построение вариационного ряда распределения и его графическое изображение позволяют получить первое представление о его наиболее характерных общих чертах. В то же время статистическое изучение совокупности не может ограничиться лишь простым упорядочением наблюдаемых величин. К тому же ряды распределения и их графики бывают довольно громоздкими, так как включают в себя всю исходную информацию. Поэтому наиболее рациональным путем статистического описания распределения будет вычисление определенных числовых характеристик, отражающих реальные свойства совокупности. К таким характеристикам прежде всего относятся характеристики центральной тенденции ряда распределения, т. е. нахождение его центрального значения; рассеивания значений признака относительно центра распределения; асимметрии и островершинности распределения. Изучение статистических характеристик распределений целесообразно начать с рассмотрения наиболее простых и в то же время чаще всего используемых в статистическом анализе, т. е. с изучения средних величин; затем научиться измерять вариацию, изучить меры скошенности и островершинности. Все эти показатели тех или иных особенностей распределения составляют единую систему статистических характеристик.
Однако применение тех или иных статистических методов предполагает прежде всего однородность изучаемой совокупности: нельзя, например, анализировать совокупность, состоящую из разных категорий хозяйств, включающую предприятия разной специализации и т. д. Для успешного решения задач необходимо глубокое понимание сущности изучаемого процесса или явления. Учитывая сложность, неоднородность экономических явлений и процессов, необходимо производить анализ таким образом, чтобы наиболее существенные различия между отдельными группами явлений не затушевывались, а выделялись для более успешного их изучения. В то же время объединение в группы сходных однотипных явлений помогает выявить их черты и особенности, которые при изучении каждого явления отдельно могут оставаться незамеченными. Выделение в каждой совокупности общественно/экономических типов явлений – главное условие ее научного анализа. А это можно осуществить, только применяя метод типологических группировок.
Массовые явления хозяйственной деятельности предприятий, являющиеся объектом статистического изучения, имеют сложный характер, обладают качественной общностью, свойственной данному явлению, но в то же время имеют и различия. Так, производством какой-либо продукции занимаются сельскохозяйственные предприятия и фермерские хозяйства и т. д. Стало быть, при характеристике производства данного вида продукции в регионе следует исходить из учета качественных особенностей предприятий, производящих эту продукцию, – в противном случае выводы будут неточными, а принимаемые на основании таких выводов решения – неэффективными.
Типологическая группировка данных – основной прием изучения экономических явлений, обеспечивающий качественную сопоставимость единиц совокупности и дающий возможность получения обобщенного количественного значения признака.
Метод группировок позволяет изучить состояние и взаимосвязи экономических явлений, если группы будут охарактеризованы показателями, раскрывающими наиболее существенные стороны изучаемого явления.
При анализе и планировании необходимо опираться не на случайные факты, а на показатели, выражающие основное, типичное, коренное. Такую характеристику дают различные виды средних величин, а также мода и медиана.
Вопрос об однородности совокупности не должен решаться формально по форме ее распределения. Его, как и вопрос о типичной средней, нужно решать, исходя из причин и условий, формирующих совокупность. Однородной является такая совокупность, единицы которой формируются под воздействием общих главных причин и условий, определяющих общий уровень данного признака, характерный для всей совокупности.
Согласно теории типологических группировок, решающее значение в оценке однородности совокупности принадлежит не форме распределения, а размеру вариации и условиям ее формирования. Для качественно однородной совокупности характерна вариация в определенных пределах, после чего начинается новое качество. Вместе с тем к этим границам для оценки качественной однородности совокупности надо подходить с точки зрения существа дела, а не формально, так как одно и то же количество в разных условиях выражает новое качество. Например, при одной и той же численности рабочих предприятия одних отраслей промышленности являются крупными, а других – мелкими.
Для всестороннего и углубленного изучения явлений, для объективной характеристики типов явлений, их взаимоотношений и процессов, обусловленных развитием системы как целого, необходимо сочетать групповые средние с общими средними. Сочетание таких средних и является одним из основных элементов анализа сложных систем. Это сочетание связывает в одно целое два органически дополняющих друг друга статистических метода: метод средних величин и метод группировки. При расчете средней индивидуальные варьирующие по группе значения заменяются одним средним значением. При этом случайные отклонения значения признака по отдельным единицам в сторону увеличения или уменьшения взаимно уравновешиваются и погашают друг друга, а в величине средней проявляется типичный размер признака, свойственный данной группе. Средняя величина служит характеристикой совокупности и в то же время относится к отдельному ее элементу – носителю качественных особенностей явления. Значение средней вполне конкретно, но одновременно и абстрактно; оно получено путем абстрагирования от случайного индивидуального по каждой единице с целью выявления того общего, типичного, что свойственно всем единицам и что формирует данную совокупность. При расчете средней величины численность единиц совокупности должна быть достаточно большой. Величина средней определяется как отношение общего объема явлений к числу единиц совокупности в группе. Для несгруппированных данных это будет средняя арифметическая простая:

а для сгруппированных данных, где каждое значение признака имеет свою частоту, – средняя арифметическая взвешенная:

где X i – значение признака; f i – частота этих значений признака.
Поскольку средняя арифметическая рассчитывается как отношение суммы значений признака к общей численности, она никогда не выходит за пределы этих значений. Средняя арифметическая обладает рядом свойств, которые широко используются в целях упорядочения расчетов.
1. Сумма отклонений индивидуальных значений признака от средней величины всегда равна нулю:

Доказательство. n
Разделив левую и правую часть на

2. Если значения признака (X i) изменить в k раз, то средняя арифметическая также изменится в x раз.
Доказательство.
Среднюю арифметическую из новых значений признака обозначим X, тогда:

Постоянную величину 1/k можно вынести за знак суммы, и тогда получим:

3. Если из всех значений признака X i вычесть или прибавить одно и то же постоянное число, то средняя арифметическая уменьшится или увеличится на эту величину.
Доказательство.
Средняя из отклонений значений признака от постоянного числа будет равна:

Точно так же доказывается это и в случае прибавления постоянного числа.
4. Если частоты всех значений признака уменьшить или увеличить в n раз, то средняя не изменится:

При наличии данных об общем объеме и известных значениях признака, но неизвестных частотах для определения среднего показателя используют формулу среднеарифметической взвешенной.
Например, имеются данные о ценах реализации капусты и общей выручке за различные сроки реализации (табл. 1).
Таблица 1.
Цена реализации капусты и общая выручка за различные сроки реализации

Так как средняя цена представляет отношение общей выручки к общему объему реализованной капусты, то вначале следует определить количество реализованной капусты по разным срокам реализации как отношение выручки к цене, а затем уже определить среднюю цену реализованной капусты.
В нашем примере средняя цена будет:

Если рассчитать в данном случае среднюю цену реализации по средней арифметической простой, то получим иной результат, который исказит истинное положение и завысит среднюю цену реализации, так как не будет учтен тот факт, что большая доля в реализации приходится на позднюю капусту с более низкой ценой.
Иногда требуется определить среднюю величину, когда значения признака даются в виде дробных чисел, т. е. обратных целым числам (например, при изучении производительности труда через обратный его показатель, трудоемкость). В таких случаях целесообразно использовать формулу средней гармонической:

Так, среднее время, необходимое для изготовления единицы продукции, есть средняя гармоническая. Если Х 1 = 1/4 часа, Х 2 = 1/2 часа, Х 3 = 1/3 часа, то средняя гармоническая этих чисел есть:
Для расчета средней величины из отношений двух одноименных показателей, например темпов роста, применяется средняя геометрическая, рассчитанная по формуле:
где Х 1 ? Х 2 … ? … Х 4 – отношение двух одноименных величин, например цепных темпов роста; n – численность совокупности отношений темпов роста.
Рассмотренные средние величины обладают свойством маорантности:
Пусть, например, имеем следующие значения Х (20; 40), тогда рассмотренные ранее виды средних величин будут равны:
При изучении состава совокупности о типичном размере признака можно судить по так называемым структурным средним – моде и медиане.
Модой называется наиболее часто встречающееся значение признака в совокупности. В интервальных вариационных рядах сначала находят модальный интервал. В найденном модальном интервале мода рассчитывается по формуле:
где Х 0 – нижняя граница модального интервала; d – величина интервала; f 1 , f 2 , f 3 – частоты предмодального, модального и послемодаль-ного интервалов.
Значение моды в интервальном ряду довольно просто можно отыскать на основе графика. Для этого в самом высоком столбце гистограммы от границ двух смежных столбцов проводят две линии. Из точки пересечения этих линий опускают перпендикуляр на ось абсцисс. Значение признака на оси абсцисс и будет модой (рис. 2).

Рис. 2
Для решения практических задач наибольший интерес представляет обычно мода, выраженная в виде интервала, а не дискретным числом. Объясняется это назначением моды, которая должна выявить наиболее распространенные размеры явления.
Средняя – величина, типичная для всех единиц однородной совокупности. Мода – тоже типичная величина, но она определяет непосредственно размер признака, свойственный хотя и значительной части, но все же не всей совокупности. Она имеет большое значение для решения некоторых задач, например для прогнозирования того, какие размеры обуви, одежды должны быть предназначены для массового производства, и т. д.
Медиана – значение признака, находящееся посредине ранжированного ряда. Она указывает на центр распределения единиц совокупности и делит ее на две равные части.
Медиана является лучшей характеристикой центральной тенденции, когда границы крайних интервалов открыты. Медиана является более приемлемой характеристикой уровня распределения и в том случае, если в ряду распределения имеются чрезмерно большие или чрезмерно малые значения, которые оказывают сильное влияние на среднюю величину, а на медиану – нет. Медиана, кроме того, обладает свойством линейного минимума: сумма абсолютных значений отклонений величины признака у всех единиц совокупности от медианы минимальная, т. е.
Это свойство имеет большое значение для решения некоторых практических задач – например, для расчета самого короткого из всех возможных расстояний для разных видов транспорта, для размещения станций техобслуживания таким образом, чтобы расстояние до всех обслуживаемых данной станцией машин было минимальным, и т. п.
При отыскании медианы сначала определяется ее порядковый номер в ряду распределения:

Далее, соответственно порядковому номеру, по накопленным частотам ряда находят саму медиану. В дискретном ряду – без всякого расчета, а в интервальном ряду, зная порядковый номер медианы, по накопленным частотам отыскивается медианный интервал, в котором путем простейшего приема интерполяции определяется уже значение медианы. Расчет медианы осуществляется по формуле:

где Х 0 – нижняя граница медианного интервала; d – величина интервала; f _ 1 – частота, накопленная до медианного интервала; f – частота медианного интервала.
Рассчитаем среднюю величину, моду и медиану на примере интервального распределения. Данные приведены в табл. 2.

Таким образом, в качестве центра распределения могут быть использованы различные показатели: средняя величина, мода и медиана,

и каждая из этих характеристик имеет свои особенности. Так, для средней величины характерно то, что все отклонения от нее отдельных значений признака взаимно погашаются, т. е.
Для медианы характерно то, что сумма отклонений индивидуальных значений признака от нее (без учета знаков) является минимальной. Мода же характеризует наиболее часто встречающееся значение признака. Поэтому в зависимости от того, какая из особенностей интересует исследователя, и должна выбираться одна из рассмотренных характеристик. В отдельных случаях рассчитываются все характеристики.
Их сравнение и выявление соотношений между ними помогает выяснить особенности распределения того или иного вариационного ряда. Так, в симметричных рядах, как в нашем случае, все три характеристики (средняя, мода и медиана) примерно совпадают. Чем больше расхождение между модой и средней величиной, тем более асимметричен ряд. Установлено, что для умеренно асимметричных рядов разность между модой и средней арифметической примерно в три раза превышает разность между медианой и средней арифметической:
Это соотношение можно использовать для определения одного показателя по двум известным. Из этого следует, что сочетание моды, медианы и средней важно и для характеристики типа распределения.
Статистическое описание совокупности было бы неполным, если ограничиться лишь показателями центральной тенденции, т. е. средними величинами, модой и медианой, которые являются равнодействующими ряда изменяющихся значений признака. В одних случаях значение признака концентрируется возле некоторого центра очень тесно, в других случаях наблюдается значительное рассеивание, хотя средняя величина может быть одинаковой. В связи с этим средняя величина как показатель центральной тенденции не дает исчерпывающей характеристики изучаемой совокупности. Возникает необходимость изучения характера рассеивания признака. Хотя отклонения от средней и регулируются общими для всех единиц совокупности причинами, формирующими среднюю, но в то же время они обусловлены и индивидуальными причинами. Например, отклонения производительности труда отдельных рабочих, работающих в одной бригаде, а стало быть, находящихся в одинаковых условиях труда, вызваны не общими условиями и причинами, а индивидуальными обстоятельствами рабочих и их квалификацией, состоянием здоровья, настроением, сообразительностью и т. д. Поэтому изучение отклонений от средней их размеров и закономерности распределения представляет большой интерес для исследователя. Это важно прежде всего для оценки однородности совокупности, которую характеризует данная средняя величина, так как для качественно однородной совокупности характерна вариация в определенных границах. Стало быть, чем меньше вариация, тем качественно однороднее совокупность, тем типичнее и объективнее средняя величина, характеризующая ее.
Измерение вариации имеет большое значение и для изучения устойчивости изучаемых экономических явлений и процессов. Так, для сельского хозяйства очень важно не только получить среднюю урожайность сельскохозяйственных культур, но и обеспечить ее устойчивость во времени и пространстве, а для этого надо научиться рассчитывать показатели устойчивости, научиться измерять вариацию изучаемых явлений? ? 1,25а .
Для оценки вариации признака статистика знает и использует несколько показателей. Простейшим из них является размах вариации, рассчитываемый по формуле: X max – X min , т. е. как разность между максимальным и минимальным значением признака. Однако этот показатель далеко не совершенен, так как при его построении участвуют лишь крайние значения признака, которые могут быть случайными.
Более точно можно определить вариацию признака при помощи показателя, учитывающего отклонения всех значений признака от средней. Это так называемые абсолютные показатели: среднее линейное отклонение а и среднее квадратическое отклонение?. Среднее линейное отклонение – это средняя арифметическая из абсолютных значений отклонений отдельных значений признака от средней величины. Но сумма отклонений от средней
всегда равна нулю (одно из свойств средней величины), поэтому для расчета среднего линейного отклонения суммируют абсолютные отклонения без учета его знака:

Среднее квадратическое отклонение также может быть простое и взвешенное:

Среднее квадратическое отклонение является наиболее распространенным показателем вариации, оно несколько больше среднего линейного отклонения. Установлено, что в симметричных или умеренно асимметричных распределениях соотношение между ними можно записать в виде:
1,25а .
Следует иметь также в виду, что среднее линейное отклонение будет минимальным, если оно рассчитано от медианы, т. е.:

Среднее квадратическое отклонение минимально при вычислении его от средней арифметической, это же относится и к дисперсии, которая представляет собой квадрат среднего квадратического отклонения.
Дисперсия

широко применяется в дисперсионном анализе, но не как мера вариации, так как ее размерность не соответствует размерности признака.
Рассмотрим вычисление среднего линейного и среднего квадрати-ческого отклонения на примере данных, приведенных в табл. 3.
Таблица 3.
Анализ времени обработки деталей рабочими двух бригад

Средняя величина времени обработки детали составляет в обеих бригадах 124 мин. Для первой бригады Х 1 =992/8 = 124ми н. и для второй – Х 2 = 1240/10 = 124 мин.
Медианные значения также одинаковы в обеих бригадах. Так, для первой бригады Хме = (116+132)/2 = 124 мин. Для второй бригады – Хме = (122+126)/2 + 124 мин
Модальные значения в данном случае не могут быть определены, так как каждое из значений признаков не повторяется.
Исходя из полученных результатов, можно сделать вывод, что обе совокупности характеризуются одинаковыми показателями центра распределения, но они могут отличаться по характеру рассеяния отдельных значений признака вокруг этих центров.
Для характеристики рассеяния рассчитаем среднее линейное отклонение. Для первой бригады:

Сопоставление среднего линейного и среднего квадратического отклонений говорит о том, что вариации времени обработки деталей в первой бригаде значительно выше, чем во второй бригаде.
Следует также отметить, что среднее квадратическое отклонение в обоих случаях несколько больше, чем среднее линейное отклонение:
1 = 1,22а 1 ;
2 = 1,20а 2 .
Это говорит о том, что мы имеем дело с умеренно асимметричным распределением.
Рассмотренные показатели вариации (размах вариации, среднее линейное отклонение, среднее квадратическое отклонение) дают возможность сравнить степень однородности нескольких совокупностей, но в отношении лишь одного признака, поскольку это именованные величины, имеющие единицы измерения те же, что и сам признак.
Однако часто исследователю приходится сравнивать вариации различных признаков, а стало быть, эти показатели вариации не могут быть использованы.
Для характеристики вариации различных признаков рассчитывают относительные показатели вариации, приведенные к одному основанию, т. е. выраженные в процентах (доли размаха вариации, среднего линейного отклонения и среднего квадратического отклонения) от средней величины изучаемого признака.
Это так называемые коэффициент осцилляции, относительное отклонение и коэффициент вариации.
Коэффициент осцилляции рассчитывается по формуле:

В нашем примере эти показатели составляют:

Все рассчитанные относительные показатели вариации свидетельствуют также о более сильной вариации времени обработки деталей рабочими первой бригады по сравнению со второй, где среднее время обработки является более объективной, более типичной характеристикой работы данной бригады в целом, т. е. вторая бригада как совокупность более однородна.
Относительные показатели вариации, как уже было отмечено, позволяют сравнивать степень вариации признаков, имеющих одинаковые единицы измерения, но разные уровни средних. Например, урожайность зерновых культур и картофеля хотя и имеют одинаковые единицы измерения, но по абсолютным показателям вариации этих признаков сравнивать было бы неправильно, так как сами уровни урожайности зерновых и картофеля резко отличаются. Так, например, в регионе среднеквадратическое отклонение составило: по урожайности ржи – 5 центнеров с гектара (ц/га) и по урожайности картофеля – 20 ц/га, а сама урожайность ржи составила 25 ц/га, а картофеля – 200 ц/га. Коэффициент же вариации соответственно равен:
Это означает, что по урожайности картофеля совокупность хозяйств данной области более однородна, чем по урожайности ржи, т. е. урожайность картофеля более устойчива, чем урожайность ржи.
Сравнение абсолютных показателей вариации одного и того же признака разных совокупностей иногда приводит к иному выводу, чем при сопоставлении относительных показателей вариации.
Так, если в одной совокупности абсолютный показатель вариации больше, чем в другой, и средний уровень изучаемого признака в ней также значительно больше, чем в другой, то относительный показатель вариации может быть ниже.
Так, например, если среднее квадратическое отклонение урожайности ржи в одном районе составило 5 ц, в другом – 3 ц, а сама средняя урожайность, соответственно, составила 25 и 10 ц/га, то относительные показатели вариации приводят к иному выводу.
Следовательно, рост урожайности, связанный с некоторым повышением абсолютного показателя вариации, может и не снизить ее устойчивости.
Относительные показатели вариации необходимы также и для сравнения вариации различных признаков, имеющих разные единицы измерения, поскольку абсолютные показатели вариации в этом случае не могут быть использованы как мера вариации.
Например, при сравнении вариации урожайности и себестоимости той или иной культуры нельзя использовать абсолютные показатели вариации, так как они будут иметь разные единицы измерения: ц/га и руб. за 1 т. В этом случае целесообразно среднее квадратическое отклонение использовать для расчета так называемого нормированного отклонения:

характеризующее отклонение индивидуальных значений признака от средней (Xi ?X ) и приходящееся на единицу среднего квадратического отклонения. Нормированное отклонение позволяет сопоставлять между собой отклонения, выраженные в различных единицах измерения. Практически нормированные отклонения изменяются в пределах от 0 до 3.
Однако в совокупности могут встречаться отдельные единицы, у которых t > 3. Это будет свидетельствовать о неоднородности совокупности, и такие единицы совокупности целесообразно исключить как аномальные, нетипичные для данной совокупности.
Если совокупность мала (3 ? n ? 8), то однородность совокупности, т. е. проверку годности первичных данных, можно осуществить следующим образом. Вычисляют показатель, характеризующий отношение разности между сомнительным и соседним значениями ранжированного в порядке возрастания ряда к разности между крайними значениями, т. е.:

если вызывает сомнение первое в ряду значение признака, и:
если вызывает сомнение последнее в ряду значение признака.
Вычисленную величину Q сопоставляют с табличным ее значением для данного числа наблюдений и уровня вероятности. Если Q ф > Q табл, то сомнительное значение следует исключить из обработки. Если же Q ф < Q табл, то сомнительное значение не отбрасывается. Рассмотрим эту методику на примере.
Допустим, получены следующие результаты содержания золы в образцах корма в процентах: 2,25; 2,19; 2,11; 2,38; 2,32 и 3,21.
Располагаем данные анализа в порядке возрастания их значений: 2,11; 2,19; 2,25; 2,32; 2,38; 3,21.
Вычисляем:

Таблица 4. Значения Q в зависимости от степени надежности (p)
и общего числа значений признака (n)
Величина Q табл = 0,70. Следовательно, значение 3,21 должно быть исключено как нетипичное для данной совокупности.
При числе значений признака больше трех (и больше восьми) можно использовать другую методику определения пригодности первичных данных. По всем значениям признака в совокупности сначала рассчитывают среднюю величину (Х) и среднее квадратическое отклонение (?), затем на основании разницы (без учета знака) между максимально отклоняющимся значением (X max) и средней величиной находят величину критерия R max по формуле:

Значение R max сопоставляют с табличным его значением при данном числе значений признака для вероятности p = 0,99 (табл. 5).
Если R max > R табл, то сомнительное значение (X) следует исключить, если же R max < R табл, то значение (X max) следует принимать в расчет.
При n > 20 показатель R max ? 3 и условие пригодности имеет вид:

Таблица 5. Значения R max для степени надежности p = 0,99 в зависимости
от числа единиц совокупности n

Обратимся к предыдущему примеру и вычислим:

При расчете средней величины и среднего квадратического отклонения используют все значения признака. Затем рассчитываем:

Для n = 6, R табл _ 2,13; так как 2,22 > 2,13, то сомнительное значение 3,21 необходимо отбросить из статистической обработки. Если сомнение вызывает не одно, а несколько значений, то сначала производят указанные выше расчеты только для одного из них (наиболее отклоняющегося). После его исключения повторяют расчет для следующего сомнительного значения, вычисляя заново X и?.
При проверке годности данных с использованием любой методики может быть исключено не более одной трети единиц совокупности.
Если исключению подлежит более одной трети всех единиц совокупности, то данная совокупность считается неоднородной.
При изучении экономических явлений статистика встречается с разнообразной вариацией признаков, характеризующих отдельные единицы совокупностей. Величины признаков варьируют под воздействием различных причин и условий. Чем разнообразнее условия, влияющие на размер признака, тем больше его вариация.
Рассмотренные показатели центральной тенденции и показатели вариации представляют собой частные случаи некоторой единой системы статистических характеристик распределения. Такая единая система характеристик может быть представлена моментами статистического распределения. Если при вычислении моментов за произвольную постоянную принимается средняя арифметическая, то такие моменты называются центральными.
Общая формула центральных моментов k-го порядка имеет вид:

Иначе говоря, центральные моменты k-го порядка представляют собой среднюю арифметическую из k – x степеней отклонений значений признака от средней арифметической.
1. Центральный момент нулевого порядка равен единице при k = 0:

2. Центральный момент первого порядка равен нулю при k = 1:

3. Центральный момент второго порядка представляет собой дисперсию данного распределения при k = 2:

4. Центральный момент третьего порядка имеет вид:

Если распределение симметричное, то нетрудно видеть, что центральный момент третьего порядка равен нулю, так как минусовые отклонения (X i – X ) 3 в левой ветви распределения будут уравновешиваться положительными отклонениями в правой части. Такое взаимное погашение отклонений в симметричных рядах распределения сохраняет силу для всех нечетных центральных моментов.
Статистика – это общественная наука, изучающая количественную сторону массовых общественных явлений в неразрывной связи с их качественной стороной.
Статистика изучает количественно определенные качества массовых социально-экономических явлений . Существует несколько точек зрения на статистику как на науку:
(1) Статистика – это универсальная наука, изучающая массовые явления природы и общества.
(2) Статистика – это методологическая наука, разрабатывающая методы исследования для других наук.
(3) Статистика – это общественная наука.
Явления общественной жизни – это сложное сочетание различных элементов.
– Общественные явления обладают вполне конкретными размерами.
– Общественным явлениям присущи определенные количественные соотношения, и существуют они независимо от того, изучает ли их статистика или нет.
1. Статистическая совокупность – это множество единиц изучаемого явления, объединенных единой качественной основой, общей связью, но отличающихся друг от друга отдельными признаками. Таковы, например, совокупность домохозяйств, совокупность семей, совокупность предприятий, фирм, объединений и т.п.
Совокупность называется однородной, если один или несколько изучаемых существенных признаков ее объектов являются общими для всех единиц.
Совокупность, в которую входят явления разного типа, считается разнородной. Совокупность может быть однородна в одном отношении и разнородна в другом. В каждом отдельном случае однородность совокупности устанавливается путем проведения качественного анализа, выяснения содержания изучаемого общественного явления.
2. Признак – это качественная особенность единицы совокупности.
По характеру выражения различают атрибутивные и
количественные признаки:
Атрибутивные (описательные) – выражаются словесно, например, пол, национальность, образование и др. По ним можно получить итоговые сведения о количестве статистических единиц, обладающих данным значением признака;
количественные – выражаются числовой мерой (возраст, стаж работы, объем продаж, размер дохода и т.д.) По ним можно получить итоговые данные о количестве единиц, обладающих конкретным значением признака, и суммарное или среднее значение признака по совокупности.
По характеру вариации признаки делятся на:
альтернативные - могут принимать только одно из двух возможных значений признака. Это признаки обладания или не обладания чем-либо. Например, пол, семейное положение, в маркетинговых или политологических исследованиях - ответ на вопрос в форме «да или нет»;
дискретные – количественные признаки принимающие только отдельные значения, без промежуточных между ними - как правило целочисленные, например, разряд рабочего, число детей в семье и т.д.);
непрерывные – количественные признаки, принимающие любые значения. На практике они, как правило, округляются в соответствии с принятой точностью (например: бухгалтерская прибыль по балансу в рублях, налоговая по налоговым регистрам – в тыс. руб.
По отношению ко времени различают:
моментные признаки, характеризующие единицы совокупности на критический момент времени например, стоимость основных производственных фондов (ОПФ) определяется на 01.01. и 31.12 соответствующего года как стоимость ОПФ на начало и конец отчётного года;
интервальные признаки, характеризующие явление за определённый временной период ((год, квартал, месяц и т.д.), например, сменная выработка, дневная выручка, годовой объём продаж и т.д.
По характеру взаимосвязи признаки делятся на:
факторные , вызывающие изменения других признаков, либо создающие возможности для изменений значений других признаков. Факторные признаки подразделяются соответственно на признаки причины и признаки условия;
результативные (признаки следствия), зависящие от вариации других признаков. Например, стоимостной объём выпуска продукции является результативным признаком, величина которого зависит от факторных признаков - численности работников и производительности труда.
3. Статистический показатель – это количественная оценка свойства изучаемого явления. Статистические показатели можно подразделить на два основных вида: учетно-оценочные показатели (размеры, объемы, уровни изучаемого явления) и аналитические показатели (относительные и средние величины, показатели вариации и т.д.).
Массовый характер общественных законов и своеобразие их действий предопределяет необходимость исследования совокупных данных.
Закон больших чисел порожден особыми свойствами массовых явлений. Последние в силу своей индивидуальности, с одной стороны, отличаются друг от друга, а с другой – имеют нечто общее, обусловленное их принадлежностью к определенному классу, виду. Причем единичные явления в большей степени подвержены воздействию случайных факторов, нежели их совокупность.
Закон больших чисел в наиболее простой форме гласит, что количественные закономерности массовых явлений отчетливо проявляются лишь в достаточно большом их числе.
Таким образом, сущность его заключается в том, что в числах, получающихся в результате массового наблюдения, выступают определенные правильности, которые не могут быть обнаружены в небольшом числе фактов.
Закон больших чисел выражает диалектику случайного и необходимого. В результате взаимопогашения случайных отклонений средние величины, исчисленные для величины одного и того же вида, становятся типичными, отражающими действия постоянных и существенных фактов в данных условиях места и времени.
Тенденции и закономерности, вскрытые с помощью закона больших чисел, имеют силу лишь как массовые тенденции, но не как законы для каждого отдельного случая.
Статистические закономерности изучают распределение единиц статистического множества по отдельным признакам под воздействием всей совокупности факторов.
Статистическая закономерность выступает как объективная закономерность сложного массового процесса и является формой причинной связи. Она обнаруживается в итоге массового статистического наблюдения. Этим обуславливается ее связь с законом больших чисел.
Статистическая закономерность с определенной вероятностью гарантирует устойчивость средних величин при сохранении постоянного комплекса условий, порождающих данное явление.
Известно, что наличие в совокупности двух групп индивидуумов (например, мужчин и женщин), средние значения изучаемых признаков которых различаются между собой, может привести к ложной корреляции. Ложная корреляция возникает тогда, когда неоднородность проявляется по тем признакам, между которыми определяют связь. На проблему неоднородности указывал Коллер . Корреляция может быть вызвана, например, различием между полами, хотя при рассмотрении групп, состоящих только из мужчин или из женщин, связь между исследуемыми признаками отсутствует. На рис. 8.4 схематично изображен этот случай. Неоднородность данных может, наоборот, затушевать корреляцию или изменить ее знак.
Рис. 8.4. Схематичный пример возникновения корреляции из-за неоднородности данных. Между изучаемыми признаками и у как для группы мужчин, так и для группы женщин не существует связи. Но так как у группы мужчин все значения признаков и у больше, чем у женщин, то коэффициент корреляции, вычисленный в целом по обеим группам, получается значительным по величине
Так как факторный анализ исходит из корреляций между переменными, то неоднородность данных оказывает влияние также на факторное решение. На это обращал внимание уже Тэрстоун . Далее на нескольких примерах, сконструированных как модели, показывается влияние неоднородности на факторную структуру. Для этого привлекается числовой пример, с которым мы уже ранее имели дело (табл. 7.5 и 7.6).
К матрице данных рассмотренного примера добавляется вторая матрица с данными, представляющими результат наблюдения над теми же самыми 10 переменными у 200 индивидуумов. Определяется корреляционная матрица по всем данным. При этом переменные и 2-й группы наблюдений приводятся к стандартной форме. Среднее значение стандартизованных переменных равно нулю, а стандартное отклонение - единице. Коэффициенты корреляции между этими переменными равны коэффициентам корреляции, указанным в табл. 7.6, т. е. факторная структура двух корреляционных матриц известна, и они идентичны. Если ко всем значениям переменных второй группы данных прибавить постоянную величину, то их средние значения станут равными этой постоянной величине. Коэффициенты корреляции между переменными для этой группы данных не изменятся.
Если принять эту постоянную величину а равной 3, то объединенная совокупность данных будет отличаться своей неоднородностью. Можно показать, что если первоначальный коэффициент корреляции между двумя переменными, принадлежащими двум группам данных, равен , то коэффициент корреляции, вычисленный по объединенной совокупности данных при указанных выше условиях, будет равен

где являются постоянными, на величину которых смещаются средние значения переменных х и у. Через X и У обозначены переменные объединенной совокупности данйых. Введем новую переменную, обозначив ее через Y. Причем она будет принимать значение, равное нулю, для индивидуума, принадлежащего к первой группе данных, и принимать значение, равное единице, для индивидуума, принадлежащего ко второй группе данных . Коэффициент корреляции между этой новой переменной Y и переменной X для объединенной совокупности данных равен:

С помощью этих двух формул были вычислены соответствующие коэффиценты корреляции по элементам корреляционной матрицы, приведенной в табл. 7.6, причем вводились различные условия, вызывающие неоднородность данных. Затем по полученным корреляционным матрицам был проведен факторный анализ, включающий в себя варимакс-вращение, и было проведено сравнение с результатом варимакс-решения в табл. 7.5.
Пример 1. Прибавляем ко всем значениям первой переменной во второй группе данных постоянную . Коэффициенты корреляции между ней и другими переменными изменяются по сравнению со значениями, приведенными в табл. 7.6. В табл. 8.1 представлены лишь те коэффициенты корреляции, величина которых изменилась по сравнению с указанными в табл. 7.6.
Пример 2. Включаем в матрицу данных 11-ю переменную, чтобы проследить влияние неоднородности данных на факторное решение. Маркировочная переменная принимает значение, равное нулю, для индивидуума, принадлежащего к первой группе данных, и значение, равное единице, для индивидуума, принадлежащего ко второй группе данных.
Таблица 8.1. Коэффициенты корреляции, изменившиеся по сравнению с приведенными в табл. 7.6 из-за неоднородности данных

Коэффициенты корреляции между этой переменной и остальными переменными, вычисленными по выборке, состоящей из 400 индивидуумов, также указаны в табл. 8.1. Результаты факторизации корреляционных матриц этих двух примеров с применением варимакс-вращения приведены в табл. 8.4, где они противопоставлены первоначальному факторному решению, полученному по однородным данным. Если причиной неоднородности является преобразование одной переменной, то факторное отображение изменяется лишь постольку, поскольку общность этой переменной уменьшается. Лишь во втором примере маркировочная переменная 11 вызывает появление третьего фактора, фактора неоднородности, и значительно его нагружает. В то время как отдельные коэффициенты корреляции при введении неоднородности уменьшились, факторное отображение изменилось незначительно. Неоднородность, обусловленная новой переменной, вызвала появление нового фактора.
Пример 3. К значениям первых трех переменных второй матрицы исходных данных прибавляем постоянную , т. е. усиливаем неоднородность данных.
Пример 4. Дополнительно к условиям примера 3 вводим маркировочную переменную 11.
Корреляционная матрица этих двух примеров приведена в нижнем углу табл. 8.2. При сравнении с табл. 7.6. бросается в глаза, что из-за неоднородности данных некоторые коэффициенты корреляции изменяются очень сильно (например, коэффициент корреляции между 2-й и 3-й переменными изменил свое значение - 0,546 на + 0,524!). Несмотря на это, факторное отображение изменилось мало, что видно из табл. 8.4, так как наряду с неоднородностью еще действуют первоначальные связи между переменными и факторами. Но нагрузки переменных 1-3 на первый фактор уменьшились. В обоих последних примерах возникает третий фактор, вызванный неоднородностью данных. Он имеет значительные нагрузки от переменных 1-3, а также 11.
Примеры 5 и 6. К значениям первых пяти переменных прибавляем постоянную величину . Эти переменные нагружают первый фактор. Следовательно, неоднородность присуща тем переменным, которые определяют первый фактор. Такая ситуация осложняет обнаружение влияния неоднородности на этот фактор. В примере 6 дополнительно вводится маркировочная переменная. Корреляционная матрица для этих двух примеров приведена в правом верхнем углу табл. 8.2.
Таблица 8.2. Корреляционные матрицы для примеров 3 и 4 (в нижнем левом углу) и для примеров 5 и 6 (в верхнем правом углу)
(см. скан)
Из табл. 8.4 видно, что в результате процедур факторного анализа -деляются три фактора. Третий фактор определяется переменными 1-5 и его появление вызвано введением неоднородности. По сравнению с исходным факторным отображением нагрузки второго фактора остаются практически без изменения, а у некоторых нагрузок первого фактора изменяются знаки. Нагрузки факторов I и III от переменных 1-5 положительны и носят противоположный характер. Содержательная интерпретация первого фактора в данном примере вызвала бы значительные затруднения. Маркировочная переменная в примере 6 показывает, что неоднородность данных сыграла определенную роль в изменении нагрузок первого фактора.
Примеры 7 и 8. К значениям 1-й и 3-й переменных прибавляется постоянная к значениям 2-й переменной - постоянная Корреляционная матрица приведена в левом нижнем углу табл. 8.3. Некоторые коэффициенты корреляции в этой матрице значительно изменились по сравнению с элементами исходной матрицы и матрицы примеров 3 и 4. В примере 7 неоднородность данных полностью обусловливает появление третьего фактора, который имеет высокие положительные нагрузки от 1-й и 3-й переменных и высокую отрицательную нагрузку от 2-й переменной. Следовательно, неоднородность здесь выступает как отдельный фактор - фактор неоднородности 1. Маркировочная переменная показывает, что неоднородность данных почти не повлияла на факторы I и II.
Примеры 9 и 10. К значениям 1, 3 и 5-й переменных прибавляется постоянная а к значениям 2-й и 4-й переменных - постоянная Корреляционная матрица приведена в верхнем правом углу табл. 8.3. В этом случае фактор неоднородности совпадает с первым фактором. Следствием этого является усиление связи первых пяти переменных с первым фактором, и его нагрузки от этих переменных увеличиваются по сравнению с исходными. Структура фактора и знаки его нагрузок не изменяются. Факторное решение примера 10 после применения процедуры варимакс-вращения совпадает в основном с факторным решением примера 9 и из-за отсутствия места в таблице не приводится 2.
Приведенные примеры, в которых моделировалась неоднородность, позволяют сделать следующие выводы:
1. Неоднородность данных может привести к появлению фактора, обусловленного только этой неоднородностью Если он совпадает с каким-либо фактором, то нагрузки этого фактора увеличиваются по сравнению с исходными.
Таблица 8.3. Корреляционные матрицы для примеров 7 и 8 (в нижнем левом углу) и для примеров 9 и 10 (в верхнем правом углу)
(см. скан)
Таблица 8.4. Варимакс-решения, полученные для различных примеров
(см. скан)
Введение маркировочной переменной помогает выявить влияние фактора неоднородности.
2. Неоднородность данных изменяет факторное отображение. При больших изменениях в корреляционной матрице в факторном отображении совершенно неожиданно могут произойти лишь незначительные изменения. Факторный анализ менее чувствителен к влиянию неоднородности, чем отдельные коэффициенты корреляции, потому что неоднородность может появиться в факторном решении как отдельный фактор и его можно исключить. Но в некоторых случаях фактор неоднородности может совпадать с каким-либо действующим фактором. Тогда отображение этого фактора изменится.
3. Факторы, которые выделяются по матрице коэффициентов корреляций между переменными с помощью техники R, могут являться следствием как корреляции между переменными, так и неоднородностей в материале исследования. Это следует помнить при интерпретации факторов. Итак, имеются два типа факторов: факторы, которые определяются действием связей между переменными, и факторы, причиной которых является неоднородность данных. Кроме того, имеются смешанные факторы. В наших примерах процедуры факторного анализа осуществлялись вслепую, но мы смогли выявить все типы факторов и определить влияние неоднородности в каждом случае.
Если бы анализировались связи между индивидуумами по выборке переменных (т. е. использовалась бы техника Q для определения независимых друг от друга группировок индивидуумов), то результаты были бы аналогичные, а именно получили бы факторы, характеризующие различные группировки, и фактор, вызванный неоднородностью данных. Такой результат не является неожиданным, так как матрица исходных данных для обеих техник одна и та же. В зависимости от постановки задачи неоднородность может рассматриваться как фактор, искажающий результаты исследования, который нужно исключать, либо, наоборот, как фактор, вводимый специально для того, чтобы проследить изменение факторного решения. В любом случае неоднородность в данных не является препятствием проведения факторного анализа. Неоднородность как раз может быть выявлена благодаря факторному анализу и исключена из решения, особенно если для признака неоднородности подобрать маркировочную переменную. В принципе оба типа факторов всегда присутствуют в экспериментальном материале.

Элементы которой принадлежат к различным типам явлений.
Словарь бизнес-терминов. Академик.ру . 2001 .
неоднородная совокупность - (напр. ядерных энергетических установок) [А.С.Гольдберг. Англо русский энергетический словарь. 2006 г.] Тематики энергетика в целом EN heterogeneous population … Справочник технического переводчика
СОВОКУПНОСТЬ, КАЧЕСТВЕННО НЕОДНОРОДНАЯ - статистическая совокупность, единицы (элементы) которой принадлежат к различным типам явлений. Качественно однородным и неоднородным совокупностям свойственна соответственно низкая или очень высокая вариация значений изучаемых признаков, для… … Большой экономический словарь
Теория исключения неизвестных из системы алгебраич. уравнений. Более точно, пусть имеется система уравнений где fi многочлены с коэффициентами из заданного поля Р. Задача исключения неизвестных х 1 ,..., х k из системы (1) (неоднородная задача… … Математическая энциклопедия
ГОСТ 16887-71: Разделение жидких неоднородных систем методами фильтрования и центрифугирования. Термины и определения - Терминология ГОСТ 16887 71: Разделение жидких неоднородных систем методами фильтрования и центрифугирования. Термины и определения оригинал документа: 70. Активная зона фильтра Участок фильтра непрерывного действия, на котором осуществляется тот… …
ГОСТ 18238-72: Линии передачи сверхвысоких частот. Термины и определения - Терминология ГОСТ 18238 72: Линии передачи сверхвысоких частот. Термины и определения оригинал документа: 19. Бегущая волна Электромагнитная волна определенного типа, распространяющаяся в линии передачи только в одном направлении Определения… … Словарь-справочник терминов нормативно-технической документации
Мировая экономика - (World Economy) Мировая экономика это совокупность национальных хозяйств, объединенных различными видами связей Становление и этапы развития мировой экономики, ее структура и формы, мировой экономический кризис и тенденции дальнейшего развития… … Энциклопедия инвестора
Явление, возникающеепри падении звуковой волны на границу раздела двух упругих сред и состоящеев образовании волн, распространяющихся от границы раздела в ту же среду … Физическая энциклопедия
Горная порода - (Rock) Горная порода это совокупнность минералов, образующая самостоятельное тело в земной коре, вследстие природных явлений Группы горных пород, магматические и метаморфические горные породы, осадочные и метасоматические горные породы, строение… … Энциклопедия инвестора
Земля (от общеславянского зем пол, низ), третья по порядку от Солнца планета Солнечной системы, астрономический знак Å или, ♀. I. Введение З. занимает пятое место по размеру и массе среди больших планет, но из планет т. н. земной группы, в… …
I Земля (от общеславянского зем пол, низ) третья по порядку от Солнца планета Солнечной системы, астрономический знак ⊕ или, ♀. I. Введение З. занимает пятое место по размеру и массе среди больших планет, но из планет т … Большая советская энциклопедия